A microlith is a monolithic application designed to shatter into microservices when hit with gentle taps from a programming hammer.
It is an intermediary step between a monolithic application and a distributed application, containing within its monolithic form the protostructure of a future microservice application.
The word microlith comprises the "micro" from microservices and the "lith" from monolith, reflecting its function as an intermediary.
Software Architects are often in a quandary when it comes to designing modern business applications. Should they design the application as a monolith or as a distributed application based on a microservice architecture?
Here are two general rules to follow: Don't start with a microservices architecture first, if you can avoid it. And don't move to a microservices architecture until real-world data shows you need to make that move. Put another way, don't burden yourself with the extra complexity of a distributed computing system until you can prove that complexity is required.
But what if you do not have the data to prove that you require microservices? Well, welcome to the microlith. Microlithic architecture lets you defer the decision to build microservices until you have real world evidence you need a distributed architecture.
But, what if the real-world data from your running microlith shows you don't need microservices? Then a microlith is a pretty good architecture to go forward with, delivering some benefits of microservices without the pain. A microlith is a well-architected monolith.
Let's consider the monolith. A monolith is a single unified software application that runs within one computer, often connected to a database running on another computer. It is one code base. It is self-contained. It performs all the functions required by the business for that application, typically including: presenting the user interface (or an API for the user interface to use), the business logic, data validation, the data access layer, and the database.
A monolith is faster and cheaper to develop, costing less to run in production than a distributed system. But monoliths risk hitting scaling limits if user demand for the application becomes significant.
Correctly designed, a modern monolith can scale vertically to handle many transactions per second, especially when running on high-end servers with plenty of RAM and connections to a fast database. However, there is a limit to how far you can scale with a monolith.
Alternatively, microservices can take advantage of modern cloud infrastructure to scale horizontally far beyond the limits of a monolith. But, because they are distributed applications, microservices are inherently more complex, requiring more time to develop and test, more developers to write them, and more cloud resources to run.
So, when considering monoliths or microservices, how is an architect to choose between these two options?
Done well, microservices can deliver high scalability. What's more, microservices are trendy. After all, are you really a software architect if you don't design microservices?
But, regarding your client's business needs, what if a microservice architecture proves to be overkill?
Maybe the application will never need to scale beyond what a monolith can handle? If that turns out to be true, then by using microservices, your design has robbed your client. By forcing unneeded expenditure on development and testing, and burdening them with higher than needed operational costs. Not to mention loss of sales and momentum from delays entering their target market.
Unfortunately, as a software architect, you don't have a crystal ball to rub. You can't know for sure what sort of scaling your application will actually need. This is because you don't know beforehand what the reaction to the business offering will be. Maybe everyone on the planet will want to use this application or perhaps the uptake will not meet the predictions?
Therefore, since you can't know, you might make the safe bet and go with microservices, just in case. After all, if the application needs massive scaling, then you've got your bases covered.
Or maybe you risk it, and build a monolith first and convince your client that if their offering takes off, then they'll have enough to fund a significant second project to convert the application into microservices.
A third option, solving this dilemma of forced early commitment to a monolith or microservices architecture, is the essential purpose of the microlith. Building a microlith allows you to hedge your bets. It allows you to wait until you are certain about user demand before committing fully to a microservices architecture.
If the predicted demand never eventuates, then the microlith's monolithic nature allows your client to continue servicing their customers without suffering the extra expense of microservices.
However, if the real world business results trend upwards, showing that the microlith's monolithic nature is going to be a problem, then the microlith's microservice protostructure allows you to quickly split off all, or parts, of the microlith into highly scalable microservices.
Microliths offer an intermediary step between monoliths and microservices, delivering greater business flexibility by not locking you in early to either architecture. Allowing you to defer your decision and so make a better, more informed choice based on the foundation of actual data.
Consider a microlith when you believe microservices seem to make sense, but you do not want to go to the expense of building and running microservices until you are sure the overhead is justified.
Flowchart 1.0 shows a suggested reasoning process to use when choosing between monolith, microlith, or microservices architectures.
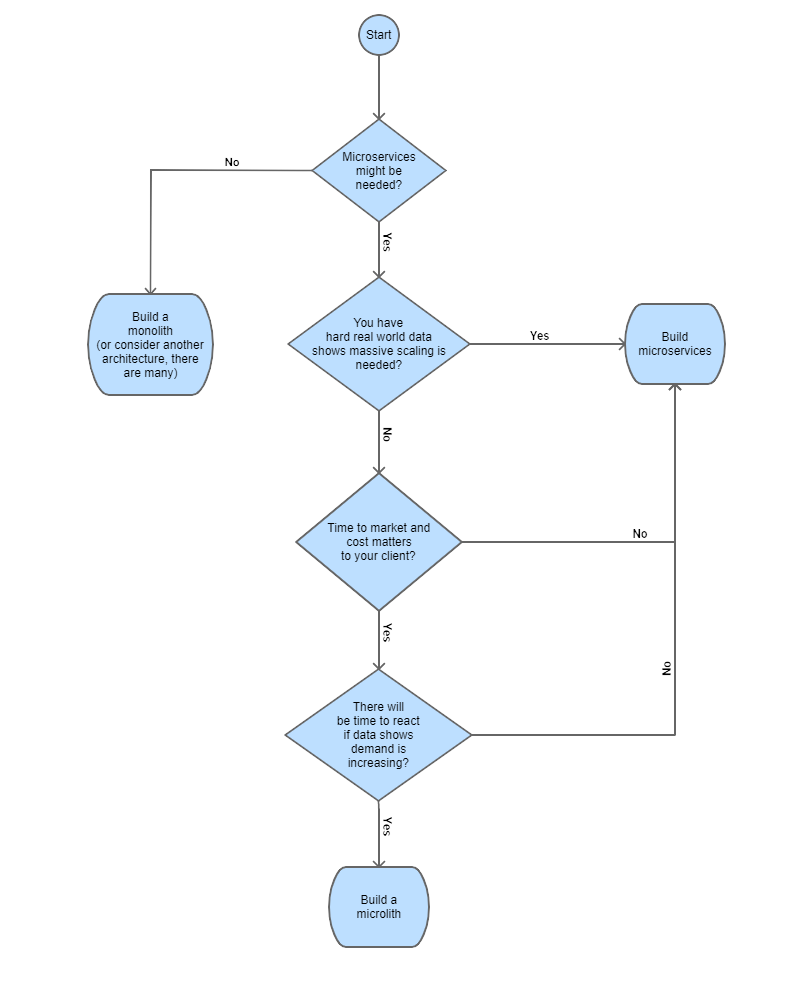
First, decide if microservices likely make sense for your application. For example, if the application is for internal use and doesn't involve heavy processing, then microservices are not required. But if the application is going to be offered to customers outside of the organization at a potentially significant scale, then microservices could make sense.
Second, are you certain the scaling provided by microservices is needed? Do you have hard real-world data on this, or are you and the business just hoping this demand will eventuate?
Third, does time to market and/or cost matter to your client? If it does, then seriously consider that before you commit to the extra time and expense of microservices.
Finally, do you believe that as demand on the application increases that you'll have time to meet that demand by extracting the microlith's segments into microservices?
If you have reached the bottom of the flowchart, then designing a microlithic architecture likely is the best choice.
Defining Boundary Contexts
The most important aspect of designing a microlith is establishing its internal segmentation, because segmentation along the optimum boundaries enables its later fracturing into separate microservices.
For both microlithic and microservices architectures, the discerning of these segment boundaries is the tough part (do everything you can to delimit these boundaries correctly early on; and if you discover you got it wrong, go back and move the boundaries).
Since a microlith's segmentation needs to be on the same boundaries that would be used for delimiting microservices, it follows that the procedure used for defining segmentation of a microlith should be the same procedure you would use to delimit microservice boundaries.
Domain-driven Design focuses on the core business domains of the application, and maps those to an implementation. A key aspect of domain-driven design is the bounded context, which allows areas of functionality to be segmented along boundaries that match best with the business domain.
Therefore, domain-driven design is a good fit for defining the boundary contexts that delimit each internal microlith segment, since these bounded contexts aim to create high cohesion within each context and low coupling between the contexts. Exactly what is needed to define each microlith segment and the coordination and communication between them.
Employing the bounded contexts from domain-driven design, the architect can define clear responsibility and boundaries for each segment of the microlith.
And so, domain-driven design is recommended as the first port of call for defining a microlith's segments. However, if domain-driven design does not result in a useful segmentation model, then there are other methods to consider, such as segmentation by business capabilities, user journeys, data ownership, or transactions.
Give a significant amount of attention to defining of the microlith's segments. Both in the planning phase and during the application development iterations.
Do not be afraid to make segmentation changes during the development phase, even if they are painful, since better segmentation improves the application and makes easier any future splitting into microservices.
Remember, a microlithic application adroitly segmented along optimum boundaries makes later conversion into microservices faster and less expensive.
A microlith is an application expressed as a single entity; a monolith, that is internally segmented along domain boundaries in the same way microservices are.
Note, this paper uses the term "segment"; but you could also call these internal segments "modules", "subdomains", "contexts" or "components".
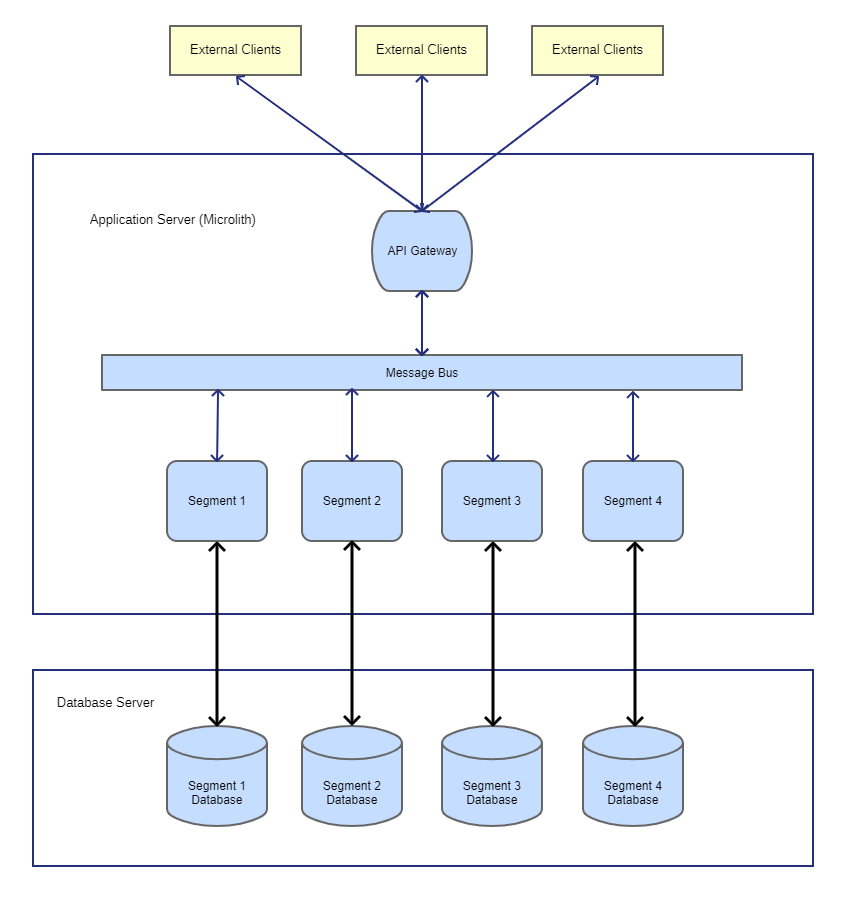
All synchronous or asynchronous communication is routed between microlith segments through an internal API for each segment, in the same way microservices communicate exclusively, between themselves, over well defined APIs (normally via a publish-subscribe message bus). The segments will need to know how to call other segments since there is no integration hub, which unfortunately implies some minimal coupling (the saga pattern and workflow owners can help avoid coupling, but come with their own complications).
Each microlith segment has its own database, which helps enforce data isolation; but that database is likely running on the same database server as the other segment's databases. Segments can have multiple databases of different types if needed, and those databases can run on different servers if required. The only rule is that each microlith segment has their own database(s), and it's forbidden for segments to interact with the databases of other segments.
A microlith has an exposed internal API gateway to present a single API for external clients. External clients do not need to know about the segment structure behind the API gateway. (Although, this is not a stringent rule, since sometimes having separate APIs and endpoints for each segment makes sense.)
The microlith communicates between the segments internally exclusively through the segments APIs, ideally over an application internal message bus. This enforces adherence to segment boundaries and helps to better simulate a microservice architecture.
However, the architecture also allows each segment to call the other segment's APIs directly, although this will make it more difficult to move to microservices later, and so is not recommended. (If you need to call a segment's API directly for performance reasons, then it's likely your segmentation will not perform because of network latency if ever extracted into microservices.)
As an option, you can create multiple instances of each segment and destroy them internally as needed, simulating microservices' ability to have more than one instance of a particular microservice. Even if not used often in the application, implementing multiple segment instances ensures a clearer picture of how a future microservices conversion will interact.
This diagram gives an example of microlith architecture. There are many variations on how to build a microlith, so don't take this as diagram as the only way.
In a microlith, cross-cutting concerns like logging, monitoring, security and configuration ought to be implemented with forward-looking consideration to what would best suit the application if split apart into microservices. Options include using a microservices chassis, or the sidecar pattern forming a service mesh.
Once chosen, implement that method in the microlith in such a way that the interfaces would seem (from each segment's perspective) to remain the same if split apart into microservices.
Finally, this example of the microlithic architecture is not set in stone. Don't see it as a dictate. The general rule is this: imagine your application composed of microservices, and make the microlith's internal structure close as possible to how it would be if that were the case.
As an intermediary, microliths share attributes of both monoliths and microservices. These following tables layout the benefits and trade-offs inherent with each of these three architectures.
|
Architectural Comparison |
|||
|
Monolithic |
Microlithic |
Microservice |
|
|
Distributed Architecture? |
No |
No |
Yes |
|
Application Internals Segmented by Business Domains? |
No |
Yes - ideally |
Yes - ideally |
|
Communications Between Boundaries Strictly Over Defined Interfaces? |
No |
Yes |
Yes |
|
Communications Between Boundaries Over Network? |
No |
No |
Yes |
|
Business Process Dependencies Crossing Segments or Services |
No |
Likely - But easy to manage changes since in one codebase |
Likely - logical dependences are hard to isolate to one service, it is hard to find the right boundaries |
|
Data Duplication |
No |
Likely - to keep to the rule of one database per segment, and to avoid too many cross segment calls |
Likely - depending on contexts and network timing issues |
|
Data Consistency |
Easy |
Medium - data might be stored in different databases, but they are on one system. Unlikely one will fail while the others do not |
Hard - cross service transactions are needed to ensure that all writes happen, or rollback occurs if one service's write fails. Data replication and synchronization is complex |
|
Data Aggregation Required |
No |
Maybe |
Yes - for complex reporting for example |
|
Individual Development Teams Per Segment? |
No |
No |
Yes - ideally |
|
Database Separation |
Normally One Database |
Multiple Databases, often on same server. |
Multiple Databases, normally on different servers |
|
Business & System Logic Duplication |
No |
Possible - try to favor duplication over coupling |
Possible - it is likely one team will duplicate logic that is present in another service. Changing logic in one service will not update the duplicate |
|
Coupling |
Tight |
Low |
Low |
|
Asynchronous Inter-Segment Communications |
No |
Ideally |
Yes - with retry and fault tolerance capabilities |
|
Number of APIs |
For Client Interfaces Only |
More - for Client Interfaces and each Segment |
More - for Client Interfaces and each Segment |
|
Ease of Design |
Easy |
Harder |
Hard |
|
Serialization & Deserialization |
No |
Depends - best not to internally JSON encode requests |
Yes - this is slow |
|
Inherent Network Latency |
No |
No |
Yes |
|
Security Endpoint Processing Delay |
No |
No |
Yes, endpoint security verification with each call |
|
Easy to Separate Out Services |
No |
Yes |
N/A |
|
Attack Surface Area |
Small |
Medium - large API endpoint |
Large - many network and API endpoints to configure and protect |
|
Risk of Segmenting Important Work Flows (i.e. user registration, checkout) |
No |
Yes - but without network latency it won't seem so bad (it is still bad) |
Yes - network latency becomes an issue, and it's hard to maintain work flows across boundaries |
|
Risk of Cross Service Transactions |
No |
Yes - too many are a sign you need to visit the scope of your segment boundaries |
Yes - can require fixes such as saga mediator services with fiddly pending states or undo mechanisms. And Eventual Consistency is more difficult than simple ACID transactions |
|
Must Mitigate the "Eight Fallacies of Distributed Computing" |
A Little - since most interprocess communications are internal to one server |
A Little - since most interprocess communications are internal to one server |
Yes - very much so, since there are many interprocess communications traveling over the network |
|
Cross Cutting Concerns? |
|||
|
Monolithic |
Microlithic |
Microservice |
|
|
Logging |
No |
Yes (across segments within app) |
Yes |
|
Authentication & Authorization |
No |
Yes (across segments within app) |
Yes |
|
Retry Processing |
No |
Yes (across segments within app) |
Yes |
|
Alerts |
No |
Yes (across segments within app) |
Yes |
|
Monitoring |
No |
Yes (across segments within app) |
Yes |
|
Configuration |
No |
Yes (across segments within app) |
Yes |
|
Tracing |
No |
Yes (across segments within app) |
Yes - Distributed Tracing |
|
Security |
No |
Yes (across segments within app) |
Yes - found a new vulnerability? Then every service might need updating |
|
Fault Tolerance Measures |
No |
Perhaps |
Required |
|
Development and Deployment |
|||
|
Monolithic |
Microlithic |
Microservice |
|
|
Time Required To Design Application |
Least |
Medium - takes more time to design than a monolith because segmentation and communications must be defined |
Most - includes the extra time to segment and design communications, plus many extras inherent to a distributed application |
|
Suitable for Small Dev Teams |
Yes |
Yes |
No - each microservice ideally should have its own development team, or you risk creating mediocre services as your team jumps between contexts |
|
Debugging Complexity |
Low |
Low |
High - distributed applications are inherently more difficult to debug |
|
Maintainability |
Low - monoliths typically ossify as time goes on as expediences are easy to take when making changes |
Medium - segmentation makes it easier as long it is strictly enforced over the application's life |
High - in theory |
|
Deployment Pipeline |
One Pipeline |
One Pipeline |
Multiple - one Pipeline Per microservice |
|
On Premise Deployments |
Easy |
Easy |
Harder - a more complex environment is required with more computing and network power, and potential licensing issues |
|
Need to Reduce Low Latency Communications |
No |
Partly - latency isn't a problem for a monolith, but the design must look to the future |
Yes |
|
Testing |
Easy |
Easy |
Harder - to set up and to coordinate testing |
|
Distributed Tracing |
No |
Not Needed - but good idea to implement transaction IDs to improve ease of moving to microservices |
Yes - transaction IDs needed, and it's more difficult tracing across a distributed system |
|
Resilience |
Low |
Medium - since errors in segments can be isolated while other segments continue functioning |
High - if loosely coupled with good data separation and business flows not affected by failure of one part, especially if multiple instances of important microservices are running |
|
Mean Time To Recovery |
The larger the monolith, the longer it can take to reboot |
The larger the microlith, the longer it can take to reboot |
Microservices are separate and small. A reboot of one or many smaller services (in parallel) can happen faster than a monolith |
|
Inter-team Communications |
Easy - there is only one team |
Easy - there is only one team |
Harder - since as extra layer of communications is needed between multiple teams |
|
Scaling |
Vertical |
Vertical |
Horizontal - distributed |
|
Tooling Needs |
Low |
Low |
High |
|
Source Control Repositories |
One |
One |
Many |
|
Code Duplication (non-DRY) |
No |
Possible - if it will help avoid coupling between segments |
Yes - unless common libraries are used, which are problematic |
|
Server Side Programming Languages |
One |
One |
One or more - with few exceptions more isn't a good thing, unless a performant language is needed for critical services |
|
Integration Testing |
Easy |
Easy |
Hard |
|
Versioning |
Easy |
Easy |
Hard - services can be changed independently of each other, making tracking versions and contract maintenance between versions difficult |
|
Primary Frameworks |
One |
One - ideally |
One to many - many isn't a good thing |
|
Ensuring Communications Between Boundaries Are Strictly Over Defined Interfaces |
Hard |
Medium - in stressful situations it can be tempting to circumvent the defined interfaces, since the application internals can be accessed easily in a monolith |
Easy |
In most cases a microlithic application will cost more than a monolith to develop, but much less than the same application built as microservices. Distributed systems are expensive to develop, deploy and run. The following table gives a relative comparison of cost areas.
|
Costs |
|||
|
Monolithic |
Microlithic |
Microservice |
|
|
Architectural Design |
Low |
Low to Medium - additional work needs to be done to define the segments boundaries and APIs |
High - much work needs to be done to define boundaries and create a distributed system |
|
Development Team(s) |
Low - one team |
Low - one team |
High - one team per microservice |
|
DevOp Team(s) |
Low - one team |
Low - one team |
High - one team per microservice |
|
Team Communications & Collaboration |
Low |
Low |
High - their is an extra layer of communications across teams |
|
Debugging Difficulty |
Low |
Low - it's all on one server, although inter segment communications adds an extra layer to contend with |
High |
|
Tooling |
Low |
Low - some extra tooling can be useful |
High - a lot of tooling is needed to run microservices at scale (larger companies often require custom in-house tooling) |
|
Testing |
Low |
Medium - there is an extra need to test communications between the segments (testing that is useful for detecting too much inter-segment communications, before any move to microservices) |
High - the number of microservices and the network layer increases the number of scenarios requiring testing, in addition to more complex security, scaling, and monitoring tests. The network layer also slows testing |
|
Time to Market (Opportunity Cost) |
Fastest |
Fast - but more work to do to than a pure monolith |
Slow - unless there are a lot of experienced resources to throw at the project |
|
Fault Tolerance |
Low |
Medium |
High |
|
Infrastructure Costs |
Low |
Low |
High |
|
Management |
Low |
Low |
High - inter-team communications and collaboration requires more management, as does management of the larger infrastructure |
A note concerning the estimating of development, deployment, infrastructure, and maintenance costs. Estimating is difficult to do for large projects with any certainty. Building a microlith first can help significantly with accurately estimating the cost of a later move to microservices.
Microliths have several advantages.
- Microliths cost less to develop and deploy than microservices. Their cost not much greater than building a monolith.
- Building a microlith first can work as a proof of concept. Delivering greater certainty that microservices will work for the implemented business application. Especially since bounded contexts are hard to define up front and the development process itself will uncover complexities not known at the project's start. The process of building a microlith allows you to clarify these contexts through the rubber-hitting-the-road process of actually building the application.
- Since setting context boundaries is likely the hardest part of building microservices, the benefit of exploring this aspect of the design in the easy to change and debug environment of a non-distributed application is significant.
- It might even be, that the attempt at building a microlith dissuades you from moving to microservices at all; preventing the suffering that would have resulted from a mismatched architecture.
- Another advantage of microliths comes with the ability to swap out message bus for another message bus that simulates network latency; allowing inter-segment messaging volumes and aggregated latency to be explored. Both these measurements allow for better insight into how the application would perform as microservices. No more go-live shocks as the application unexpectantly bogs down as hundreds of unforeseen microservice interactions transverse the slow network layer.
- Also, because you can do real world measurement in both testing and production, you might find only certain parts of your microlith are scale-bound, and that the rest performs well as a monolith. This itself is a significant cost saving over building the whole application as microservices, since it is far cheaper to separate out only the parts you have proven need to scale.
- Time to market is also an important aspect to consider. Often, the sooner a business can get its offering to market, the more successful they can be. Microservices may allow significant scalability, but the delay required to develop test and deploy microservices might mean that the expected volume never happens, especially if competitors win the market first with a faster deployment.
Microlithic architecture makes sense for certain projects. While it is not a silver bullet, it might just be a rubber bullet. A safer way of dealing with the inherent risks of building an application that seems to require the high caliber punch of a distributed computing solution.
Modern monolithic applications can handle high numbers of transactions, therefore microliths (being a monolith) can also handle a high transaction volumes. There are large SaaS (Software as a Service) companies running high volume systems as a monolith. This implies that there is a good chance you will never need to move away from your microlith.
But, if your production data shows a need to move to microservices, then you can make that move assured your decision is justified based on real-world data (instead of guesses about the future). And you can do that move backed by the trailblazing knowledge and experience you gained from building the application first as a microlith.
Finally, it is important that you don't see microlithic architecture as a set of rules. It is more of an idea. An idea you can adapt to your client's business situation as needed.
Microliths are a starting point, not a rigid blueprint. There is no reason not to take the general idea of the microlith and implement it in any way you see fit. As long as you achieve the two the primary goals of discovering the application's boundary contexts, and deferring the decision for microservices. Achieving those goals will prepare for any future work separating your microlith into microservices.
Good luck with your development experience.
The author welcomes comment and feedback via email: mark(you know what goes here)newzealandit.com
Generic example reference: Vrankovich, M. J. (2023, July 12). Microlithic software architecture. New Zealand IT Site, https://newzealandit.com/MicrolithicSoftwareArchitecture.html
(No AI text generation of any type was used in writing this paper)